Problem 9 - Implement strStr()
Leetcode Link: Implement strStr().
- Statement
- Examples
- Solution 1 - Simple Loop
- Solution 2 - Use a Deterministic Finite Automata (DFA)
- Solution 3 - Knuth-Morris-Pratt (KMP) Algorithm
Statement
Implement strStr().
Given two strings needle and haystack, return the index of the first occurrence of needle in haystack, or -1 if needle is not part of haystack.
Clarification:
What should we return when needle is an empty string? This is a great question to ask during an interview.
For the purpose of this problem, we will return 0 when needle is an empty string. This is consistent to C’s strstr() and Java’s indexOf().
Examples
Input: haystack = "hello", needle = "ll"
Output: 2
Input: haystack = "aaaaa", needle = "bba"
Output: -1
Solution 1 - Simple Loop
Concept
Assertion: Consider a string \(\text{text}\) of length \(n\) and a pattern \(\text{pattern}\) of length \(m \le n\). Then, \(\text{pattern}\) can occur in \(\text{text}\) starting at any index \(i\) such that \(0 \le i \le n - m\).
If \(\text{needle}\) is an empty string, return \(0\).
Let length of \(\text{haystack}\) be \(n\) and that of \(\text{needle}\) be \(m\).
For each \(0 \le i \le n - m\):
- If \(\text{needle} = \text{haystack}[i : i + m]\), return \(i\).
- Otherwise, continue.
Return \(-1\) by default.
Example
Input
haystack = "hello"
needle = "ll"
Procedure
- \(m = 2\)
- Iteration 1:
- \(i = 0\)
- Since \(\text{needle} \not = {\text{haystack}[0:2] = \text{he}}\), continue
- Iteration 2:
- \(i = 1\)
- Since \(\text{needle} \not = {\text{haystack}[1:3] = \text{el}}\), continue
- Iteration 3:
- \(i = 2\)
- Since \(\text{needle} = \text{haystack}[2:4] = \text{ll}\), return \(i = 2\)
Time complexity
There are a total of \(n - m + 1\) possible values for \(i\) and for each \(i\), the solution takes out a slice of length \(m\). Therefore, the time complexity is \(\mathcal{O}((n - m + 1)*m)\).
Solution 2 - Use a Deterministic Finite Automata (DFA)
Concept
To learn about DFAs, see Deterministic finite automaton.
Assertion 1: Consider a string \(\text{pattern}\) of length \(m\). Let \(A=(Q, \Sigma, \delta, q_0, F)\) be a DFA such that \(L(A)=\{w \mid w \text{ ends with pattern}\}\). Then, \(A\) has \(m + 1\) states (\(\mid Q \mid = m\)) and a single final state \(q_F\) (\(\mid F \mid = 1\)).
For example, if \(\text{pattern}=ll\), \(Q=\{0, 1, 2\}\), \(\Sigma=\{a,b,\dots,z\}\), \(q_0=0\) and \(F=\{2\}\), then \(A\) is as shown:
Assertion 2: Let \(A\) be a DFA as mentioned above with \(Q=\{0, 1, \dots, m\}\) and \(q_F=m\).
Consider a string \(\text{text}\) of length \(n\).
If \(\text{text}\) is processed through \(A\) and the final state \(q_F=m\) is reached on the character at index \(i \lt n\), then \(\text{pattern}\) exists in \(\text{text}\) and starts at index \(i - m + 1\).
Assertion 3: The empty string \(\epsilon\) is a prefix and a suffix of all strings.
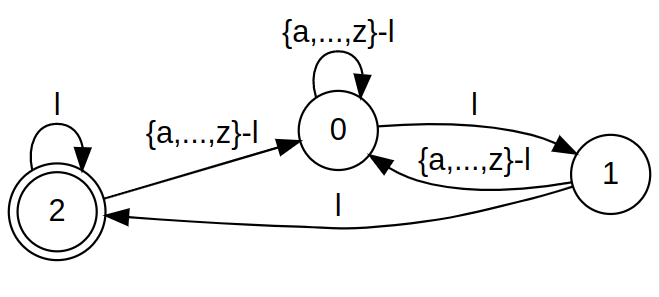
The solution is made up of three parts.
Prefix Function
The prefix function is a function \(\pi:\{0, 1, \dots, m - 1\} \rightarrow \{0, 1, \dots, m-1\}\) defined for \(\text{pattern}\) such that:
\[\pi[q] = \max \{k: k \lt q \text{ and pattern}[:k] \text{ is a suffix of pattern}[:q]\}\]In other words, \(\pi[q]\) is the length of the longest prefix of \(\text{pattern}\) that is a proper suffix (since \(k \lt q\)) of \(\text{pattern}[:q+1]\).
For example, let \(\text{pattern} = \text{ababaca}\).
The prefixes of \(\text{pattern}\) are as shown:
| \(\epsilon\) | \(\text{a}\) | \(\text{ab}\) | \(\text{aba}\) | \(\text{abab}\) | \(\text{ababa}\) | \(\text{ababac}\) | \(\text{ababaca}\) |
\(\pi\) is as shown:
| q | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| \(\text{pattern}[:q+1]\) | \(\text{a}\) | \(\text{ab}\) | \(\text{aba}\) | \(\text{abab}\) | \(\text{ababa}\) | \(\text{ababac}\) | \(\text{ababaca}\) |
| Proper suffixes | \(\epsilon\) | \(\epsilon\), \(\text{b}\) | \(\epsilon\), \(\text{a}\), \(\text{ba}\) | \(\epsilon\), \(\text{b}\), \(\text{ab}\), \(\text{bab}\) | \(\epsilon\), \(\text{a}\), \(\text{ba}\), \(\text{aba}\), \(\text{baba}\) | \(\epsilon\), \(\text{c}\), \(\text{ac}\), \(\text{bac}\), \(\text{abac}\), \(\text{babac}\) | \(\epsilon\), \(\text{a}\), \(\text{ca}\), \(\text{aca}\), \(\text{baca}\), \(\text{abaca}\), \(\text{babaca}\) |
| Required prefix | \(\epsilon\) | \(\epsilon\) | \(\text{a}\) | \(\text{ab}\) | \(\text{aba}\) | \(\epsilon\) | \(\text{a}\) |
| \(\pi[q]\) | 0 | 0 | 1 | 2 | 3 | 0 | 1 |
The code for computing \(\pi\) is as follows:
def pi(pattern: str) -> list[int]:
pi = [-1] * len(pattern)
pi[0] = 0
k = 0
for idx, char in enumerate(pattern[1:], 1):
while k > 0 and pattern[k] != char:
k = pi[k - 1]
if pattern[k] == char:
k += 1
pi[idx] = k
return pi
Transition Function
Note: There is a much simpler way of computing the transition function without using \(\pi\) but it is significantly slower.
Given the prefix function \(\pi\) for \(\text{pattern}\), the transition function \(\delta\) of the DFA \(A\) as mentioned in the assertion can be created easily.
Set \(\delta(q, a) = 0\) for all \(a \in \Sigma - \{\text{pattern[0]}\}\).
Set \(\delta(0, \text{pattern[0]})=1\).
For each \(1 \le q \le m\) and \(a \in \Sigma\):
- If \(q = m\) or \(\text{pattern}[q] \not = a\), \(\delta(q, a) = \delta(\pi[q - 1], a)\)
- Otherwise, \(\delta(q, a) = q + 1\)
Running \(\text{text}\) through the DFA
Given the transition function \(\delta\), the starting position of \(\text{pattern}\) in \(\text{text}\) can be found easily.
Initialize \(q\) to \(0\), the start state of the DFA.
For each character \(a=\text{text}[i]\) in \(\text{text}\):
- Get the next state as \(q = \delta(q, a)\)
- If \(q = m\) (the final state), return \(i - m + 1\)
- Otherwise, continue
Return \(-1\) at the end.
Example
Input
haystack = "hello"
needle = "ll"
Procedure
-
Compute prefix function \(\pi\):
q 0 1 \(\pi[q]\) 0 1 -
Compute the transition function \(\delta\):
\(\delta\) \(\text{a}\) \(\text{b}\) \(\dots\) \(\text{l}\) \(\dots\) \(\text{z}\) 0 0 0 \(\dots\) 1 \(\dots\) 0 1 0 0 \(\dots\) 2 \(\dots\) 0 *2 0 0 \(\dots\) 2 \(\dots\) 0 The \(\dots\) indicates that the values are same everywhere and \(*\) indicates the final state:.
- \(q = 0\)
- Iteration 1:
- \(i = 0\)
- \(a = \text{haystack[i]} = \text{h}\)
- \(q = \delta(0, \text{h}) = 0\)
- Since \(q \not = 2\), continue.
- Iteration 2:
- \(i = 1\)
- \(a = \text{haystack[i]} = \text{e}\)
- \(q = \delta(0, \text{e}) = 0\)
- Since \(q \not = 2\), continue.
- Iteration 3:
- \(i = 2\)
- \(a = \text{haystack[i]} = \text{l}\)
- \(q = \delta(0, \text{l}) = 1\)
- Since \(q \not = 2\), continue.
- Iteration 4:
- \(i = 3\)
- \(a = \text{haystack[i]} = \text{l}\)
- \(q = \delta(1, \text{l}) = 2\)
- Since \(q = 2\), return \(i - m + 1 = 2\).
Time complexity
The prefix function can be computed in \(\mathcal{O}(m)\).
Using the prefix function, the transition function can be computed in \(\mathcal{O}(m\mid \Sigma \mid)\).
Finally, the string can be run through the DFA in \(\mathcal{O}(n)\).
Thus, the overall time complexity is \(\mathcal{O}(m\mid \Sigma \mid+n)\).